Windows PE 文件格式解析
0x0 前言
PE 文件格式是老生常谈了,网上也有各种深入解析的文章,之所以记下来当作学习轨迹吧。鉴于已有大量的手工文件分析文章,所以这次就站在开发者的角度,使用 C++ 对 PE 文件进行解析。
0x1 创建文件内存映射内核对象
使用 ReadFile 的方式来访问数据字段信息显得太过繁琐,更好的方式是将文件映射到内存中,然后就可以开开心心的使用指针和 MS 定义的数据结构来进行操作,所以先来看看如何将文件映射到内存空间,并获取内核对象句柄:
#include <Windows.h>
int main(int argc, char** argv)
{
int nRet = -1;
char* szFilename = NULL;
PVOID lpImageBase = NULL;
HANDLE hFile, hMapFile;
// 好歹你也传入个参数哇
if (argc < 2)
{
return nRet;
}
char* szFilename = argv[1];
// 1.获取文件对象句柄
hFile = CreateFile(szFilename, GENERIC_READ, FILE_SHARE_READ,
NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
if (hFile == INVALID_HANDLE_VALUE)
{
return nRet;
}
// 2.创建文件映射句柄
hMapFile = CreateFileMapping(hFile, NULL, PAGE_READONLY,
0, 0, NULL);
if (hMapFile == NULL)
{
CloseHandle(hFile);
return nRet;
}
// 3.将文件映射到虚拟内存
lpImageBase = MapViewOfFile(hMapFile, FILE_MAP_READ, 0, 0, 0);
if (lpImageBase == NULL)
{
CloseHandle(hFile);
CloseHandle(hMapFile);
return nRet;
}
/** 操作映像指针 blabla */
// 释放内核对象
UnmapViewOfFile(lpImageBase);
CloseHandle(hFile);
CloseHandle(hMapFile);
return 0;
}
因为我太懒所以并不打算解释各个函数的参数作用,具体可参考 MSDN。但是从上面的代码总结创建文件映射的基本步骤:
1. 调用 CreateFile 获取文件对象句柄
2. 使用 CreateFileMapping 创建文件映射句柄,此时文件载入到交换文件中
3. 最后使用 MapViewOfFile 将文件载入到内存
// 4. 用完别忘记释放
0x2 刮涂层辨真伪
首先在操作 PE 文件之前,需要判断该文件是否为有效的 PE 格式。正确的方法是判断 IMAGE_DOS_HEADER 的 e_magic 字段,以及 IMAGE_NT_HEADER32 的 Signature 字段。同时判断两个字段的原因在于,避免将 MZ 开头 ASCII 文本文件误判为 PE 文件,所以有必要进行二次确认:
bool IsValidPeFile()
{
bool bRet = false;
PIMAGE_DOS_HEADER pDosHdr = NULL;
PIMAGE_NT_HEADERS pNtHdr = NULL;
// lpImageBase 是整个 PE 文件映射到虚拟内存的首地址,即是 MapViewOfFile 返回值
pDosHdr = (PIMAGE_DOS_HEADER) lpImageBase;
if (pDosHdr->e_magic != IMAGE_DOS_SIGNATURE)
{
return bRet;
}
// IMAGE_DOS_HEADER 的 e_lfanew 值为 IMAGE_NT_HEADERS 的 RVA,引用时加上基址
pNtHdr = (PIMAGE_NT_HEADERS) ((DWORD) lpImageBase + pDosHdr->e_lfanew);
if (pNtHdr->Singature == IMAGE_NT_SIGNATURE)
{
bRet = true;
}
return bRet;
}
0x3 NT 头 = PE 标志 + 文件头 + 选项头
NT 头的其实是三个数据结构的组合体,其定义如下:
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER OptionalHeader;
} IMAGE_NT_HEADERS, *PIMAGE_NT_HEADERS;
文件头(IMAGE_FILE_HEADER)包含基本的 PE 信息,选项头(IMAGE_OPTIONAL_HEADER)则是扩展更多的信息,所以基本上两者可以合体。多说无益,先把 IMAGE_FILE_HEADER 解析出来:
void ShowFileHeader()
{
PIMAGE_FILE_HEADER pFileHdr = NULL;
// 假设我用黑科技变出了 pNtHdr 变量指向 IMAGE_NT_HEADERS
// 其实就是上面验证 PE 文件格式的时候获取的,但是要注意这个函数里并没有声明该变量,仅当示例
pFileHdr = pNtHdr->FileHeader;
printf("0x%04X\n", pFileHdr->Magic);
printf("%d\n", pFileHdr->NumberOfSections);
// 获取更多属性 More...
}
比较有趣的是 TimeDateStamp 字段,这个字段表明了该 PE 文件的链接时间,通过这个链接时间,我们往往可以判断一些恶意程序的新旧程度。自然,这个时间可以伪造,也可以为空。通常情况下,可以使用 time.h 下的 localtime 函数将其转换为本地时间:
#include <time.h>
char* GetLinkedTime(DWORD timestamp)
{
char* szBuffer = NULL;
struct tm *stTime = NULL;
if (timestamp == 0)
{
return NULL;
}
// 先将数据转换为 tm 结构体
stTime = localtime((time_t*) ×tamp);
if (stTime == NULL)
{
return NULL;
}
szBuffer = (char*) malloc(sizeof(char) * 80);
// 通过传入 tm 结构体,将时间格式化为可读字符串
// xxxx-xx-xx xx:xx:xx
strftime(szBuffer, sizeof(char) * 80, "%Y-%m-%d %H:%M:%S", stTime);
return szBuffer;
}
关于时间函数可参考:http://www.tutorialspoint.com/c_standard_library/time_h.htm
所以输出大概是这样子:
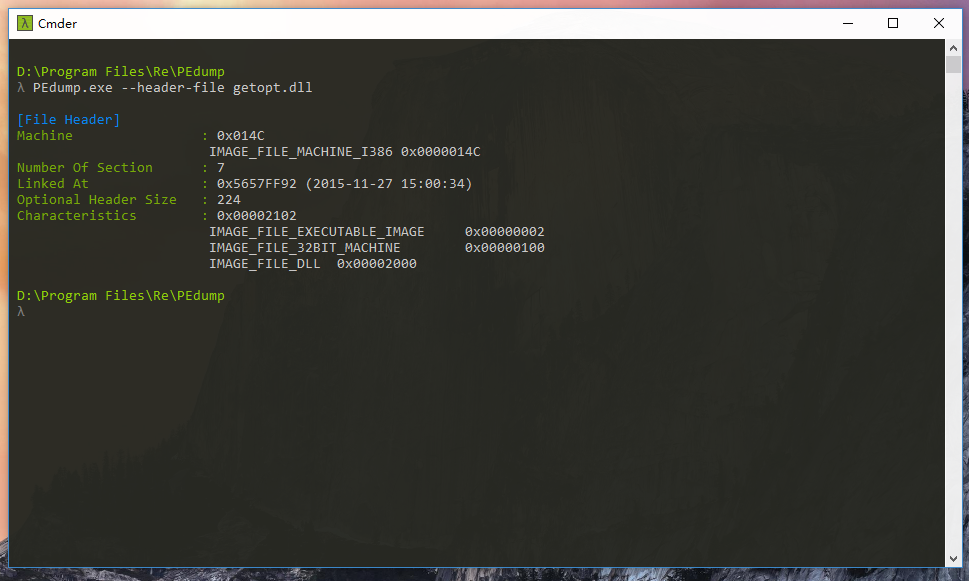
所以依样画葫芦可以列举出 IMAGE_OPTIONAL_HEADER,在此就省略了。不过在 IMAGE_OPTIONAL_HEADER 中还有一个重要的信息:数据目录。
0x4 数据目录
数据目录是 IMAGE_OPTIONAL_HEADER 中的最后一个成员,是一个长度为 16 的数组。该数组成员由 IMAGE_DATA_DIRECTORY 结构组成:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
该结构包含数据表的 RVA 和大小。因为数组的每个索引对应一个固定的数据表(例如第一个元素指向输出表),所以我们先定义一个字符数组用于存储数据表名称,并将数据目录枚举出来:
const char* DATA_DIRECTORY[] = {
"Export Table",
"Import Table",
"Resource Table",
"Exception Table",
"Security Table",
"Base relocation Table",
"Debug",
"Copyright",
"Global Pointer",
"Thread local storage",
"Load Configuration",
"Bound Import Table"},
"Import Address Table" },
"Delay Import Descriptor",
"COM Header",
"Reserved"
};
void ShowDataDirInfo()
{
int i;
PIMAGE_OPTIONAL_HEADER pOptHdr = NULL;
pOptHdr = pNtHdr->OptionalHeader;
// IMAGE_NUMBEROF_DIRECTORY_ENTRIES 是 MS 定义的宏,其值为 16
for (i = 0; i < IMAGE_NUMBEROF_DIRECTORY_ENTRIES; i++)
{
printf("%-20s\t0x%08X\t0x%08X", DATA_DIRECTORY[i],
pOptHdr->DataDirectory[i].VirtualAddress,
pOptHdr->DataDirectory[i].Size);
}
}
输出如图:
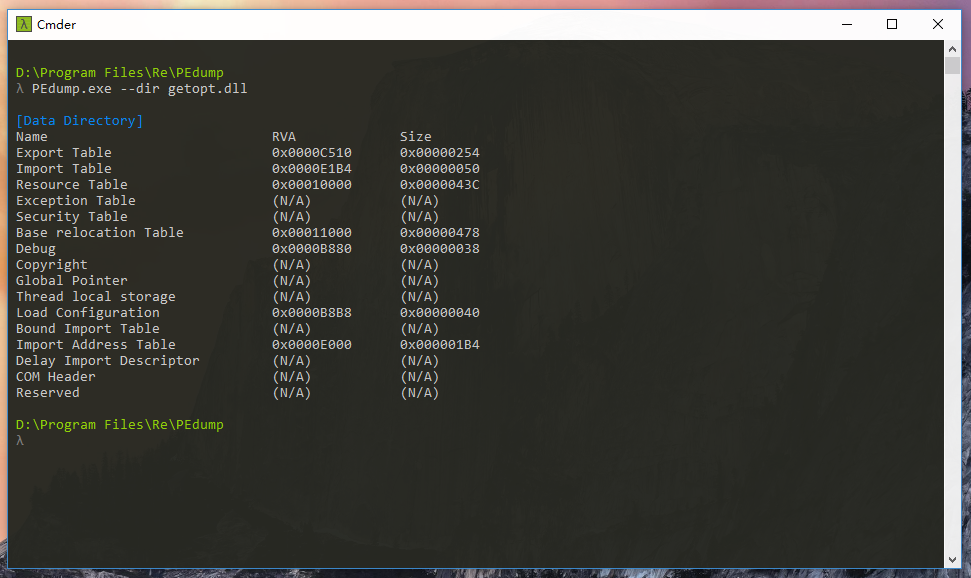
数据目录中有两个非常重要的元素:导出表(Export Table) 和 导入表(Import Table)。而 导入地址表(IAT, Import Address Table)可由导入表寻得,所以重点还是看后者。简而言之,导出表和导入表是 PE 的核心内容。
0x5 导入表
所谓导入,既是从其他的文件中引用。Windows 中的共享库为 DLL,所以当引用这些共享库的函数时,有必要将这些信息保存下来。当 PE 装载的时候,才能正确的加载共享库,并引用其中的资源。导入表同样是一个数组,其成员的数据定义如下:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk;
} DUMMYUNIONNAME;
DWORD TimeDateStamp
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR;
IMAGE_IMPORT_DESCRIPTOR 通常简称为 IID。每个 IID 描述一个 DLL 文件与其函数信息,导入表结尾以一个全 0 的 IID 填充。
0x6 INT 和 IAT
OriginalFirstThunk 指向 INT(Import Name Table,导入名称表),FirstThunk 指向 IAT(Import Address Table,导入地址表)。两个数据的结构是完全相同的:
typedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString;
DWORD Function;
DWORD Ordinal;
DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32
因为是一个 union 结构,所以其实就是一个 DWORD 类型的数据。在 INT 和 IAT 数组中,每个成员的值作为 RVA ,又指向同一个数组(绕来绕去的全是指针),这个数据最终存储 函数的名称 和 序号:
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
CHAR Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
总的来讲,整个结构如图:
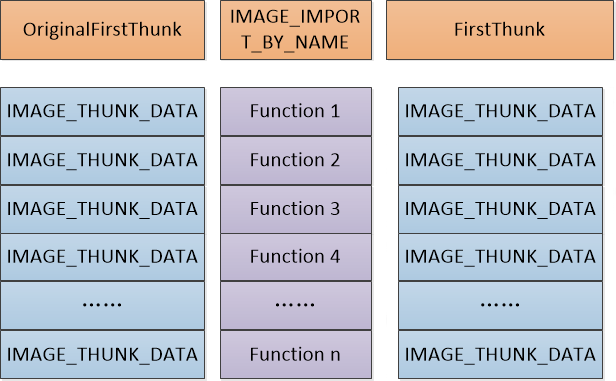
0x7 IAT 的载入流程
首先是一小段代码,获取一个文件句柄然后啥都不干:
#include <Windows.h>
int main()
{
HANDLE hFile = NULL;
hFile = CreateFile("D:\\demo.txt", GENERIC_READ, FILE_SHARE_READ, NULL,
OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
if (hFile != INVALID_HANDLE_VALUE)
{
CloseHandle(hFile);
}
return 0;
}
因为引用了 CreateFile 函数,所以导入表中保存了 Kernel32.dll 文件信息和该函数的信息。在机器代码中,并不是直接 call 到 CreateFile 的函数地址,而是通过一个间接的方式调用:
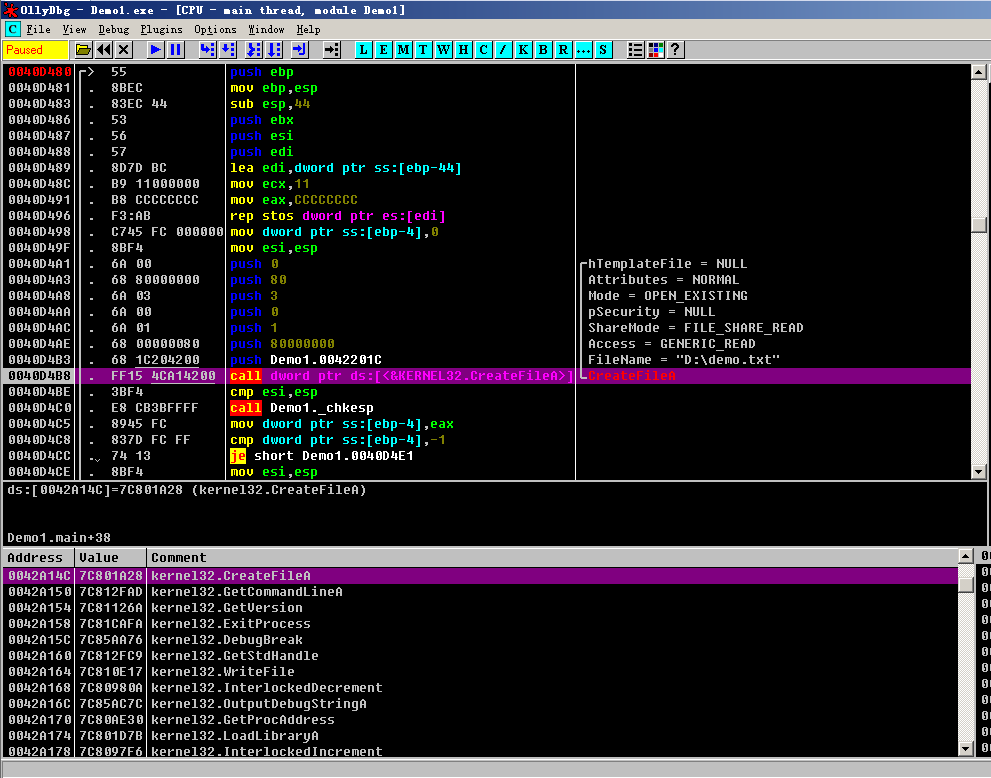
执行函数调用的机器码为 FF15 4CA14200,所以实际上是调用 0x0042A14C 处的值,这个内存区域便是 IAT。
一般来说,当 PE 文件存储在磁盘时,INT 和 IAT 指向同个数组。
一旦载入到内存中,INT 不变,但是 IAT 中的每个元素会替换为对应的函数地址,这时候就可以通过 IAT 来间接调用函数,PE 装载器也无须因为 DLL 重定向而发愁。
整个流程描述为:
1. 通过数据目录找到导入表的第一个 IID
2. 通过 IID 的 Name 字段并载入 DLL,如 LoadLibrary("Kernel32.dll")
3. 通过 OriginalFirstThunk 找到 INT
4. INT 中的每个元素为 IMAGE_IMPORT_BY_NAME 的 RVA,通过该值找到函数名称,获取函数指针,GetProcAddress("CreateFileA")
5. 通过 FirstThunk 找到 IAT,将真正的函数地址写入 IAT 中
所以 PE 被载入到内存中时,IID 的结构如图:
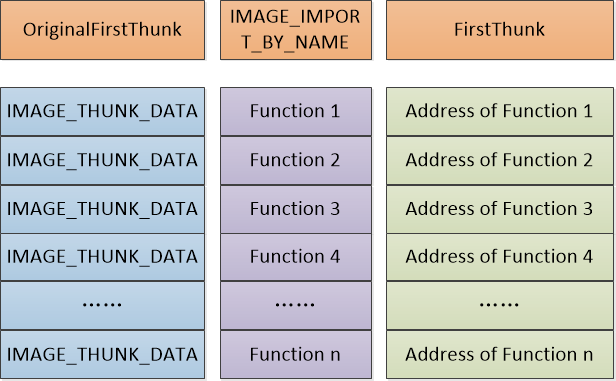
当 IAT 载入完毕后,INT 和其他的数据信息就可以忽略了(一家独大。
0x8 为什么需要两个结构相同的 IMAGE_THUNK_DATA 数组?
INT 和 IAT 的结构是完全相同的,之所以需要两个完全相同的数据,和导入绑定(Binding)有关。
首先,当 PE 载入到内存时,装载器需要遍历导入信息,并将函数地址填充到 IAT,比较耗时。为了加快加载速度,可以提前将函数地址写入到 IAT 并存储到磁盘中,提升载入速度。
但是呢,事情并没有这么简单。比如某个 DLL 的版本不同,其中的函数地址改动了,这时绑定的就是一个错误的地址。当文件重新载入到内存中时,PE 装载器必须校验这些函数地址的有效性。如果发现错误,则需要通过 INT 寻找新的函数地址,并载入到 IAT。
IAT 载入完成的时候,这些信息又可以被忽略了(尴尬。
0x9 解析导入表
从现在开始需要操作大量的 RVA,真正的虚拟地址需要加上映像基址,所以我们先实现一个转换函数:
PVOID GetVirtualAddress(DWORD dwRelVirtualAddr)
{
return (PVOID) ((DWORD) lpImageBase + dwRelVirtualAddr);
}
模仿 PE 装载器,大概思路为:通过数据目录获取第一个 IID,再循环读取 INT 读取从该 DLL 引用的函数。
void ShowIAT()
{
DWORD dwRVA = 0;
// IID 指针
PIMAGE_IMPORT_DESCRIPTOR pImportDesc = NULL;
// 楼上的一个成员指向我
PIMAGE_DATA_CHUNK pDataChunk = NULL;
// 楼上指向我
PIMAGE_IMPORT_BY_NAME pImportName = NULL;
dwRVA = pNtHdr->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress;
// 导入表被隐藏了?
if (dwRVA == 0)
{
return;
}
pImportDesc = (PIMAGE_IMPORT_DESCRIPTOR) GetVirtualAddress(dwRVA);
// 结尾为全空的 IID,所以可以通过任意字段判断是否结束
while (pImportDesc->OriginalFirstChunk)
{
// DLL 名称,注意是 RVA
printf("%s\n", (char*) GetVirtualAddress(pImportDesc->Name) );
pDataChunk = (PIMAGE_DATA_CHUNK) GetVirtualAddress(pImportDesc->OriginalFirstChunk);
while (pDataChunk->u1.AddressOfData)
{
pImportName = (PIMAGE_IMPORT_BY_NAME) GetVirtualAddress(pDataChunk->u1.AddressOfData);
// 函数序号和名称
printf("%d\t%s\n", pImportName->Hint, pImportName->Name);
pDataChunk++;
}
pImportDesc++;
}
}
效果如图:
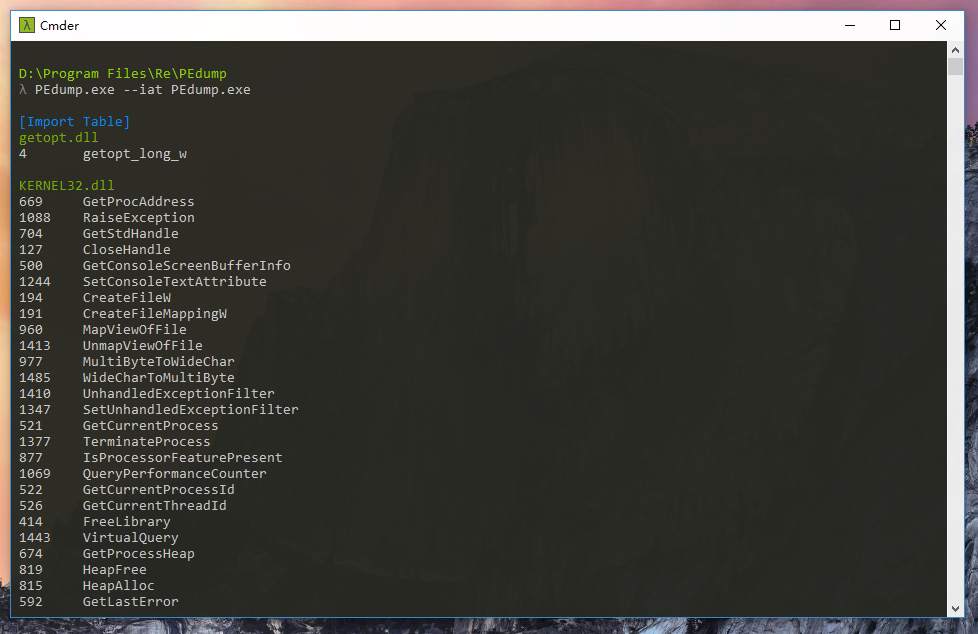
0xA 导出表
导出表描述 DLL 共享的函数信息。数据目录的第一个成员便是导出表信息,EAT 是一个 IMAGE_EXPORT_DIRECTORY 结构:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY
当载入 IAT 时,PE 装载器需要从 EAT 中获取某个函数的地址,这个是通过 GetProcAddress 函数实现的,其过程大概如下:
1. 获取 AddressOfNames 的值,得到首个函数名称字符数组的 RVA
2. 通过 strcmp 比较每个函数名称,并获取函数名称在数组中的索引 name_index
3. 通过 AddressOfNameOrdinals 找到函数序号数组,并使用 name_index 进行索引,获取正确的函数序号 ordinal
4. 使用 AddressOfFunctions 导航到函数地址数组,通过 ordinal 为索引,最后获取函数地址
为什么不直接通过 name_index 索引函数地址,而还要使用 ordinal?
0xB 导出函数地址的真正索引
首先编译一个正常的 DLL 文件:
#include <Windows.h>
void __declspec(dllexport) Create()
{
MessageBox(NULL, TEXT("Create"), TEXT("MessageBox"), 0);
};
void __declspec(dllexport) Delete()
{
MessageBox(NULL, TEXT("Delete"), TEXT("MessageBox"), 0);
};
调用 DLL 中的函数有两种方法,一种是通过函数名的方式,如 GetProcAddress(“Create”)。另一种是通过函数序号的方式:
#include <Windows.h>
// 定义函数指针原型
typedef void (__stdcall *PFUNC)();
int main()
{
PFUNC pfCreate;
HANDLE hModule = LoadLibrary(TEXT("DemoDll.dll"));
if (hModule == NULL)
{
return -1;
}
pfCreate = (PFUNC) GetProcAddress(hModule, MAKEINTRESOURCEW(1));
if (pfCreate != NULL)
{
pfCreate();
}
return 0;
}
输出结果:
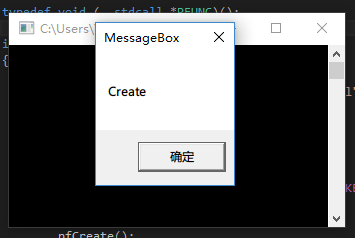
链接器链接时,会为每个导出函数分配一个函数序号。默认从 1 开始,排序方式为函数名称的 ASCII 值。例如 Create 的函数序号为 1,Delete 则为 2:

等等为啥是 0x00 和 0x01?那是因为数组都是从 0 开始索引,你不能说第二个函数的地址是 AddressOfFunctions[2],这样会造成数组越界,年轻人别总想搞个大新闻。
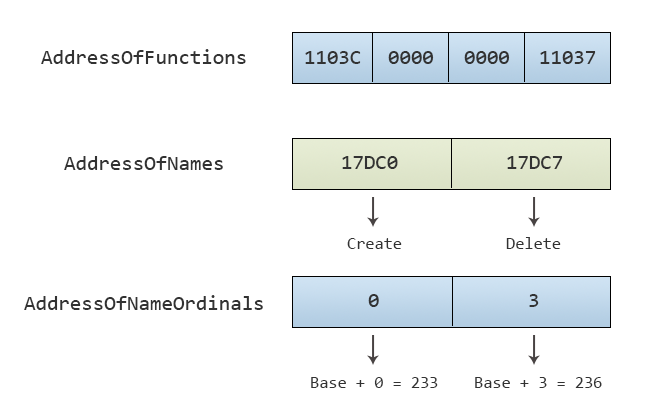
所以,AddressOfNameOrdinals 其实保存的是一个偏移值(类似 RVA)。其真实的函数序号需要加上 Base 字段的值(此处为 1,在 0x6D80 处)。
相反,如果通过函数序号取回函数指针,则函数序号在传入后,会自行减去 Base 值,得到正确的函数指针索引。
一般情况下,name_index 是等于 ordinal 的。例如 “Create” 是 AddressOfNames 的第一个元素,则 name_index = 0,因此 Create 的函数序号为 AddressOfNameOrdinals[name_index] = 0x0000 = name_index。
但是呢,你不能说 name_index 绝对等于 ordinal,并且坚决使用 name_index 来索引函数指针:因为函数序号是可以自定义的。
0xC 函数序号中的奇行种
同样是上面的 DLL,新建一个和 DLL 同名的 .def 文件:
; LIBRARY 之后为 DLL 的名称
LIBRARY DemoDll
; 自定义函数序号
EXPORTS
Create @233
Delete @236
然后将其添加到链接命令行中:
/DEF:YOUR_DEF_FILE.def
编译后使用 Stud_PE 查看,会发现一个有趣的现象:
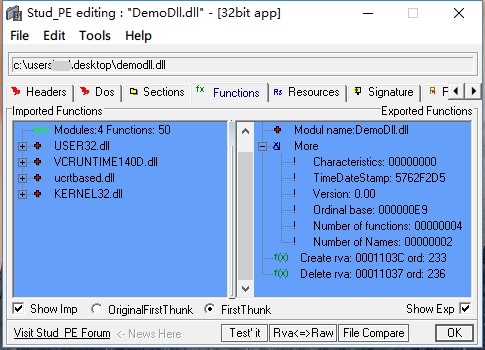
实际导出的函数为两个,但是 NumberOfFunctions 的值为 4,哦摩西咯一。

载入文件,可以看到 Base 变为 0xE9(十进制位 233,在 0x6D80 处),而 AddressOfNameOrdinals 中的两个函数序号分别为 0x00,0x03,对应的 AddressOfFunctions 成员为有效的导出函数地址(橘色标记)。而函数地址数组中,有两个成员是使用 00 填充的,这也是为什么 NumberOfFunctions 的值会为 4。
所以说,今天作为一个长者,告诉大家,name_index 不一定等于 ordinal。
0xD 解析导出表
思路同 GetProcAddress 函数一致,获取函数名称后,通过索引取得函数序号,最后获取函数地址:
void ShowEAT()
{
DWORD i, dwRVA = 0;
// 函数序号指针
WORD* pFuncOrdinal = NULL;
// 函数名称和函数地址指针
DWORD* pFuncName = NULL, *pFuncAddr = NULL;
PIMAGE_EXPORT_DIRECTORY pExportDir = NULL;
dwRVA = pNtHdr->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress;
if (dwRVA == 0)
{
return;
}
pExportDir = (PIMAGE_EXPORT_DIRECTORY) GetVirtualAddress(dwRVA);
// 导出函数为 0
if (pExportDir->NumberOfNames == 0)
{
return;
}
pFuncName = (DWORD*) GetVirtualAddress(pExportDir->AddressOfNames);
pFuncAddr = (DWORD*) GetVirtualAddress(pExportDir->AddressOfFunctions);
pFuncOrdinal = (WORD*) GetVirtualAddress(pExportDir->AddressOfNameOrdinals);
// DLL 文件名称
printf("%s\n", (char*) GetVirtualAddress(pExportDir->Name));
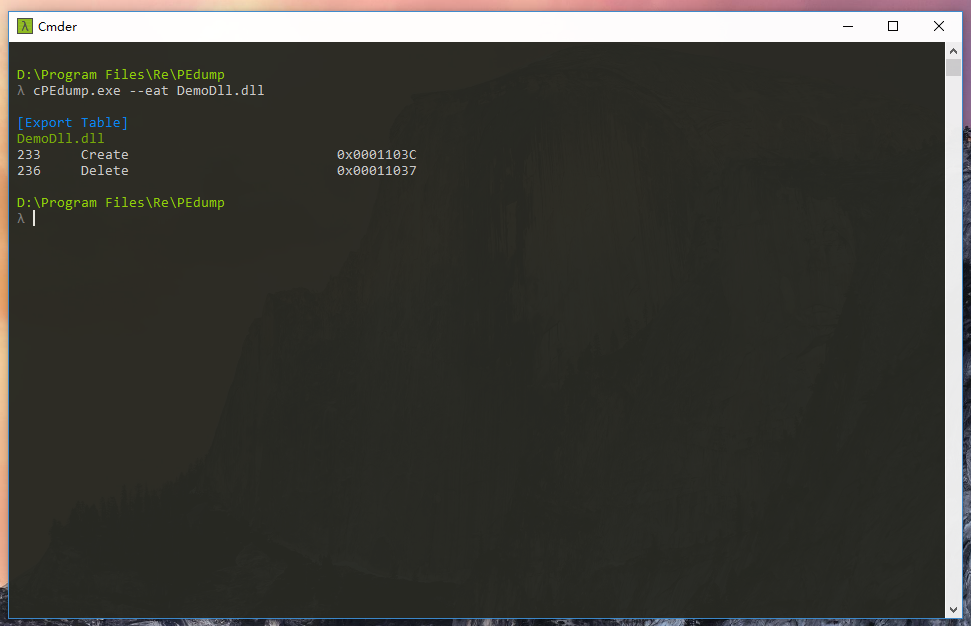
for (i = 0; i < pExportDir->NumberOfNames; i++)
{
printf("%d\t%s\t0x%08X\n", pFuncOrdinal[i] + pExportDir->Base,
(char*) pFuncName[i],
pFuncAddr[pFuncOrdinal[i]]);
}
}
输出结果:
0xE 结束语
综合整个解析过程,笔者实现了一个命令行 PEdump 工具:https://github.com/soxfmr/PEdump(其实也就是本文截图中的工具)。